

| << Chapter < Page | Chapter >> Page > |
In general, the HPF compiler is not magic - it simply does a very good job with the communication details when the programmer can design a good data decomposition. At the same time, it retains portability with the single CPU and shared uniform memory systems using FORTRAN 90.
Perhaps the most important contributions of HPF are its data layout directives. Using these directives, the programmer can control how data is laid out based on the programmer's knowledge of the data interactions. An example directive is as follows:
REAL*4 ROD(10)
!HPF$ DISTRIBUTE ROD(BLOCK)
The
!HPF$ prefix would be a comment to a non-HPF compiler and can safely be ignored by a straight FORTRAN 90 compiler. The
DISTRIBUTE directive indicates that the
ROD array is to be distributed across multiple processors. If this directive is not used, the
ROD array is allocated on one processor and communicated to the other processors as necessary. There are several distributions that can be done in each dimension:
REAL*4 BOB(100,100,100),RICH(100,100,100)
!HPF$ DISTRIBUTE BOB(BLOCK,CYCLIC,*)!HPF$ DISTRIBUTE RICH(CYCLIC(10))
These distributions operate as follows:
BLOCK The array is distributed across the processors using contiguous blocks of the index value. The blocks are made as large as possible.CYCLIC The array is distributed across the processors, mapping each successive element to the "next" processor, and when the last processor is reached, allocation starts again on the first processor.CYCLIC(n) The array is distributed the same as
CYCLIC except that
n successive elements are placed on each processor before moving on to the next processor.
Distributing array elements to processors
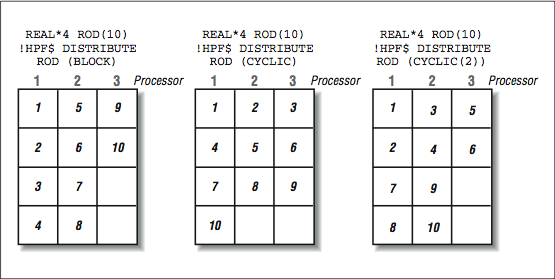
[link] shows how the elements of a simple array would be mapped onto three processors with different directives.
It must allocate four elements to Processors 1 and 2 because there is no Processor 4 available for the leftover element if it allocated three elements to Processors 1 and 2. In
[link] , the elements are allocated on successive processors, wrapping around to Processor 1 after the last processor. In
[link] , using a chunk size with
CYCLIC is a compromise between pure
BLOCK and pure
CYCLIC .
To explore the use of the
* , we can look at a simple two-dimensional array mapped onto four processors. In
[link] , we show the array layout and each cell indicates which processor will hold the data for that cell in the two-dimensional array. In
[link] , the directive decomposes in both dimensions simultaneously. This approach results in roughly square patches in the array. However, this may not be the best approach. In the following example, we use the
* to indicate that we want all the elements of a particular column to be allocated on the same processor. So, the column values equally distribute the columns across the processors. Then, all the rows in each column follow where the column has been placed. This allows unit stride for the on-processor portions of the computation and is beneficial in some applications. The
* syntax is also called
on-processor distribution.
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|
|
|