

| << Chapter < Page | Chapter >> Page > |
In the last lecture we consider a learning problem in which the optimal function belonged to a finite class of functions.Specifically, for some collection of functions with finite cardinality , we have
This is almost always not the situation in the real-world learning problems. Let us suppose we have a finite collection ofcandidate functions . Furthermore, we do not assume that the optimal function , which satisfies
where the is taken over all measurable functions, is a member of . That is, we make few, if any, assumptions about . This situation is sometimes termed as Agnostic Learning . The root of the word agnostic literally means not known . The term agnostic learning is used to emphasize the fact that often, perhaps usually, we may have no prior knowledgeabout . The question then arises about how we can reasonably select an in this setting.
The PAC style bounds discussed in the previous lecture , offer some help. Since we are selecting a function based on the empirical risk,the question is how close is to . In other words, we wish that the empirical risk is a good indicator of the true risk for every function in . If this is case, the selection of that minimizes the empirical risk
should also yield a small true risk, that is, should be close to . Finally, we can thus state our desired situation as
for small values of and . In other words, with probability at least , , . In this lecture, we will start to develop bounds of this form. First we will focus on bounding for one fixed .
To begin, let us recall the definition of empirical risk for be a collection of training data. Then the empirical risk is defined as
Note that since the training data are assumed to be i.i.d. pairs, the terms in the sum are i.i.d random variables.
Let
The collection of losses is i.i.d according to some unknown distribution (depending on the unknown joint distribution of (X,Y) and the loss function). Theexpectation of is , the true risk of . For now, let's assume that is fixed.
We know from the strong law of large numbers that the average (or empirical mean) converges almost surely to the true mean That is, almost surely as . The question is how fast.
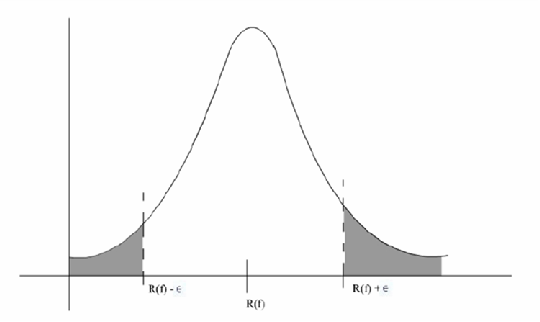
Concentration inequalities are upper bounds on how fast empirical means converge to their ensemble counterparts, in probability. The areaof the shaded tail regions in Figure 1 is . We are interested in finding out how fast this probability tends to zero as .
At this stage, we recall Markov's Inequality . Let be a nonnegative random variable.
Notification Switch
Would you like to follow the 'Statistical learning theory' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|
|

|
|

|