

| << Chapter < Page | Chapter >> Page > |
My own thinking (and that of many of my colleagues) is based on two general principles, which I shall call the Sequence Hypothesis and the Central Dogma. The direct evidence for both of them is negligible, but I have found them to be of great help in getting to grips with these very complex problems. I present them here in the hope that others can make similar use of them. Their speculative nature is emphasized by their names. It is an instructive exercise to attempt to build a useful theory without using them. One generally ends in the wilderness. The Sequence Hypothesis This has already been referred to a number of times. In its simplest form it assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that this sequence is a (simple) code for the amino acid sequence of a particular protein... The Central Dogma This states that once 'information' has passed into protein it cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information means here the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein. This is by no means universally held—Sir Macfarlane Burnet, for example, does not subscribe to it—but many workers now think along these lines. As far as I know it has not been explicitly stated before.Francis Crick, 1958
Crick's concept of the Central Dogma of Molecular Biology is a useful way to summarize a lot of what we know about nucleic acids. In both prokaryotes and eukaryotes, the second function of DNA (the first was replication) is to provide the information needed to construct the proteins necessary so that the cell can perform all of its functions. To do this, the DNA is “read” or transcribed into an mRNA molecule. The mRNA then provides the code to form a protein by a process called translation. Through the processes of transcription and translation, a protein is built with a specific sequence of amino acids that was originally encoded in the DNA. This section discusses the details of transcription.
The flow of genetic information in cells from DNA to mRNA to protein is described by the Central Dogma of Molecular Biology ( [link] ), which states that genes specify the sequences of mRNAs, which in turn specify the sequences of proteins.
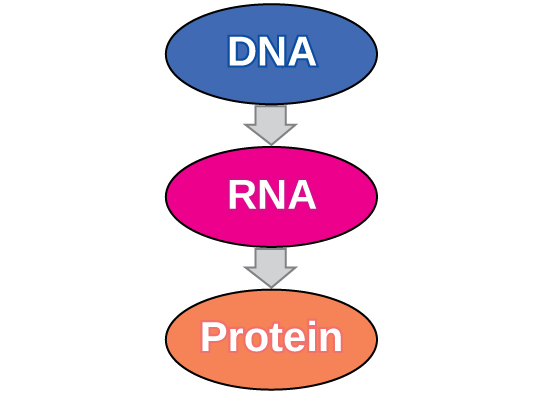
The copying of DNA to mRNA is relatively straightforward, with one nucleotide being added to the mRNA strand for every complementary nucleotide read in the DNA strand. The translation to protein is more complex because groups of three mRNA nucleotides correspond to one amino acid of the protein sequence. However, as we shall see in the next section, the translation to protein is still systematic, such that nucleotides 1 to 3 correspond to amino acid 1, nucleotides 4 to 6 correspond to amino acid 2, and so on.
Notification Switch
Would you like to follow the 'Principles of biology' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|
|

|
|
|
|