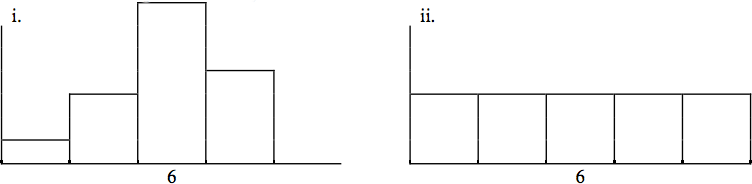
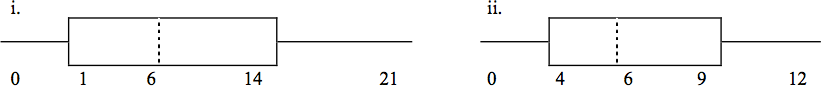Javier and Ercilia are supervisors at a shopping mall. Each was given the task of estimating the mean distance that shoppers live from the mall. They each randomly surveyed 100 shoppers. The samples yielded the following information:
Javier
Ercilla
6.0 miles
6.0 miles
4.0 miles
7.0 miles
How can you determine which survey was
correct?
Explain what the difference in the results of the surveys implies about the data.
If the two histograms depict the distribution of values for each supervisor, which one depicts Ercilia's sample? How do you know?
If the two box plots depict the distribution of values for each supervisor, which one depicts Ercilia’s sample? How do you know?
Try these multiple choice questions (exercises 24 - 30).
The next three questions refer to the following information. We are interested in the number of years students in a particular elementary statistics class have lived in California.
The information in the following table is from the entire section.
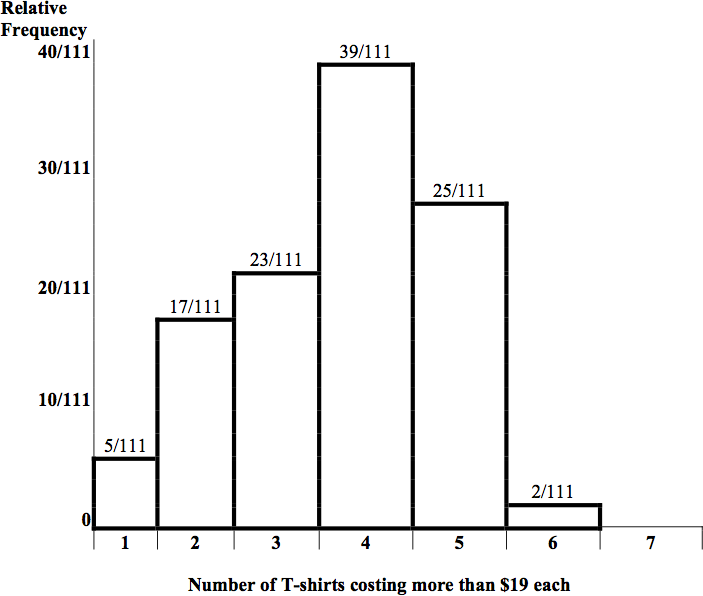
The next two questions refer to the following histogram. Suppose one hundred eleven people who shopped in a special T-shirt store were asked the number of T-shirts they own costing more than $19 each.
The percent of people that own at most three (3) T-shirts costing more than $19 each is approximately:
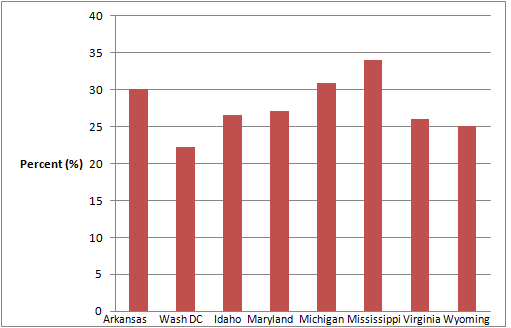
Below are the
2010 obesity rates by U.S. states and Washington, DC. (
Source: http://www.cdc.gov/obesity/data/adult.html) )
State
Percent (%)
State
Percent (%)
Alabama
32.2
Montana
23.0
Alaska
24.5
Nebraska
26.9
Arizona
24.3
Nevada
22.4
Arkansas
30.1
New Hampshire
25.0
California
24.0
New Jersey
23.8
Colorado
21.0
New Mexico
25.1
Connecticut
22.5
New York
23.9
Delaware
28.0
North Carolina
27.8
Washington, DC
22.2
North Dakota
27.2
Florida
26.6
Ohio
29.2
Georgia
29.6
Oklahoma
30.4
Hawaii
22.7
Oregon
26.8
Idaho
26.5
Pennsylvania
28.6
Illinois
28.2
Rhode Island
25.5
Indiana
29.6
South Carolina
31.5
Iowa
28.4
South Dakota
27.3
Kansas
29.4
Tennessee
30.8
Kentucky
31.3
Texas
31.0
Louisiana
31.0
Utah
22.5
Maine
26.8
Vermont
23.2
Maryland
27.1
Virginia
26.0
Massachusetts
23.0
Washington
25.5
Michigan
30.9
West Virginia
32.5
Minnesota
24.8
Wisconsin
26.3
Mississippi
34.0
Wyoming
25.1
Missouri
30.5
Construct a bar graph of obesity rates of your state and the four states closest to your state. Hint: Label the x-axis with the states.
Use a random number generator to randomly pick 8 states. Construct a bar graph of the obesity rates of those 8 states.
Construct a bar graph for all the states beginning with the letter "A."
Construct a bar graph for all the states beginning with the letter "M."
Example solution for
b using the random number generator for the Ti-84 Plus to generate a simple random sample of 8 states. Instructions are below.
Number the entries in the table 1 - 51 (Includes Washington, DC; Numbered vertically)
Press MATH
Arrow over to PRB
Press 5:randInt(
Enter 51,1,8)
Eight numbers are generated (use the right arrow key to scroll through the numbers). The numbers correspond to the numbered states (for this example: {47 21 9 23 51 13 25 4}. If any numbers are repeated, generate a different number by using 5:randInt(51,1)). Here, the states (and Washington DC) are {Arkansas, Washington DC, Idaho, Maryland, Michigan, Mississippi, Virginia, Wyoming}.
Corresponding percents are {28.7 21.8 24.5 26 28.9 32.8 25 24.6}.
A music school has budgeted to purchase 3 musical instruments. They plan to purchase a piano costing $3000, a guitar costing $550, and a drum set costing $600. The mean cost for a piano is $4,000 with a standard deviation of $2,500.
The mean cost for a guitar is $500 with a standard deviation of $200. The mean cost for drums is $700 with a standard deviation of $100. Which cost is the lowest, when compared to other instruments of the same type? Which cost is the highest when compared to other instruments of the same type. Justify your answer numerically.
For pianos, the cost of the piano is 0.4 standard deviations BELOW the mean. For guitars, the cost of the guitar is 0.25 standard deviations ABOVE the mean. For drums, the cost of the drum set is 1.0 standard deviations BELOW the mean. Of the three, the drums cost the lowest in comparison to the cost of other instruments of the same type. The guitar cost the most in comparison to the cost of other instruments of the same type.
Suppose that a publisher conducted a survey asking adult consumers the number of fiction paperback books they had purchased in the previous month. The results are summarized in the table below. (Note that this is the data presented for publisher B in homework exercise 13).
Publisher b
# of
books
Freq.
Rel.
Freq.
0
18
1
24
2
24
3
22
4
15
5
10
7
5
9
1
Are there any outliers in the data? Use an appropriate numerical test involving the IQR to identify outliers, if any, and clearly state your conclusion.
If a data value is identified as an outlier, what should be done about it?
Are any data values further than 2 standard deviations away from the mean? In some situations, statisticians may use this criteria to identify data values that are unusual, compared to the other data values. (Note that this criteria is most appropriate to use for data that is mound-shaped and symmetric, rather than for skewed data.)
Do parts (a) and (c) of this problem give the same answer?
Examine the shape of the data. Which part, (a) or (c), of this question gives a more appropriate result for this data?
Based on the shape of the data which is the most appropriate measure of center for this data: mean, median or mode?
IQR = 4 – 1 = 3 ; Q1 – 1.5*IQR = 1 – 1.5(3) = -3.5 ; Q3 + 1.5*IQR = 4 + 1.5(3) = 8.5 ;The data value of 9 is larger than 8.5. The purchase of 9 books in one month is an outlier.
The outlier should be investigated to see if there is an error or some other problem in the data; then a decision whether to include or exclude it should be made based on the particular situation.
If it was a correct value then the data value should remain in the data set. If there is a problem with this data value, then it should be corrected or removed from the data. For example: If the data was recorded incorrectly (perhaps a 9 was miscoded and the correct value was 6) then the data should be corrected. If it was an error but the correct value is not known it should be removed from the data set.
xbar – 2s = 2.45 – 2*1.88 = -1.31 ; xbar + 2s = 2.45 + 2*1.88 = 6.21 ; Using this method, the five data values of 7 books purchased and the one data value of 9 books purchased would be considered unusual.
No: part (a) identifies only the value of 9 to be an outlier but part (c) identifies both 7 and 9.
The data is skewed (to the right). It would be more appropriate to use the method involving the IQR in part (a), identifying only the one value of 9 books purchased as an outlier. Note that part (c) remarks that identifying unusual data values by using the criteria of being further than 2 standard deviations away from the mean is most appropriate when the data are mound-shaped and symmetric.
The data are skewed to the right. For skewed data it is more appropriate to use the median as a measure of center.