

| << Chapter < Page | Chapter >> Page > |
When the processor goes looking for a piece of data, the cache lines are asked all at once whether any of them has it. The cache line containing the data holds up its hand and says “I have it”; if none of them do, there is a cache miss. It then becomes a question of which cache line will be replaced with the new data. Rather than map memory locations to cache lines via an algorithm, like a direct- mapped cache, the memory system can ask the fully associative cache lines to choose among themselves which memory locations they will represent. Usually the least recently used line is the one that gets overwritten with new data. The assumption is that if the data hasn’t been used in quite a while, it is least likely to be used in the future.
Fully associative caches have superior utilization when compared to direct mapped caches. It’s difficult to find real-world examples of programs that will cause thrashing in a fully associative cache. The expense of fully associative caches is very high, in terms of size, price, and speed. The associative caches that do exist tend to be small.
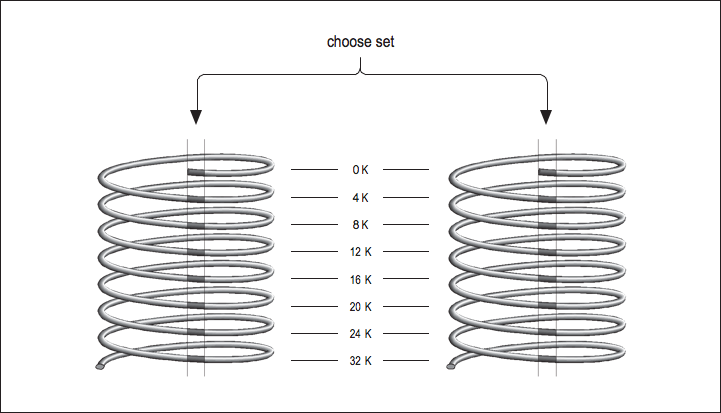
Now imagine that you have two direct mapped caches sitting side by side in a single cache unit as shown in [link] . Each memory location corresponds to a particular cache line in each of the two direct-mapped caches. The one you choose to replace during a cache miss is subject to a decision about whose line was used last — the same way the decision was made in a fully associative cache except that now there are only two choices. This is called a set-associative cache . Set-associative caches generally come in two and four separate banks of cache. These are called two-way and four-way set associative caches, respectively. Of course, there are benefits and drawbacks to each type of cache. A set-associative cache is more immune to cache thrashing than a direct-mapped cache of the same size, because for each mapping of a memory address into a cache line, there are two or more choices where it can go. The beauty of a direct-mapped cache, however, is that it’s easy to implement and, if made large enough, will perform roughly as well as a set-associative design. Your machine may contain multiple caches for several different purposes. Here’s a little program for causing thrashing in a 4-KB two-way set- associative cache:
REAL*4 A(1024), B(1024), C(1024)
COMMON /STUFF/ A,B,CDO I=1,1024
A(I) = A(I) * B(I) + C(I)END DO
END
Like the previous cache thrasher program, this forces repeated accesses to the same cache lines, except that now there are three variables contending for the choose set same mapping instead of two. Again, the way to fix it would be to change the size of the arrays or insert something in between them, in
COMMON . By the way, if you accidentally arranged a program to thrash like this, it would be hard for you to detect it — aside from a feeling that the program runs a little slow. Few vendors provide tools for measuring cache misses.
So far we have glossed over the two kinds of information you would expect to find in a cache between main memory and the CPU: instructions and data. But if you think about it, the demand for data is separate from the demand for instructions. In superscalar processors, for example, it’s possible to execute an instruction that causes a data cache miss alongside other instructions that require no data from cache at all, i.e., they operate on registers. It doesn’t seem fair that a cache miss on a data reference in one instruction should keep you from fetching other instructions because the cache is tied up. Furthermore, a cache depends on locality of reference between bits of data and other bits of data or instructions and other instructions, but what kind of interplay is there between instructions and data? It would seem possible for instructions to bump perfectly useful data from cache, or vice versa, with complete disregard for locality of reference.
Many designs from the 1980s used a single cache for both instructions and data. But newer designs are employing what is known as the Harvard Memory Architecture , where the demand for data is segregated from the demand for instructions.
Main memory is a still a single large pool, but these processors have separate data and instruction caches, possibly of different designs. By providing two independent sources for data and instructions, the aggregate rate of information coming from memory is increased, and interference between the two types of memory references is minimized. Also, instructions generally have an extremely high level of locality of reference because of the sequential nature of most programs. Because the instruction caches don’t have to be particularly large to be effective, a typical architecture is to have separate L1 caches for instructions and data and to have a combined L2 cache. For example, the IBM/Motorola PowerPC 604e has separate 32-K four-way set-associative L1 caches for instruction and data and a combined L2 cache.
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|
|
|