

| << Chapter < Page | Chapter >> Page > |
In essence, this approach was very appealing in terms of performance, development time, and cost (essentially free). Although faster and more efficient implementations are possible (e.g.
C/C++ and
Fortran with
open-MPI , the aforementioned implementation was sufficient for our purposes).
The code utilized was initially developed for sequential execution (in
SAS ) and then converted to
R with similar performance. It was subsequently converted from sequential to parallel to exploit the benefits of a parallel
R -implementation. The standard steps for this conversion process are pretty standard, essentially:
Workhorse Functions).Combine/Gather Functions).snow ).Several 64 processor jobs were submitted to Rice's
Cray XD1 Research Cluster (ADA) - occupying 16 nodes, each with a total of 4 processors. The jobs would take less than 20 hours to complete, for about 64 simulated tracks of 40 years each.
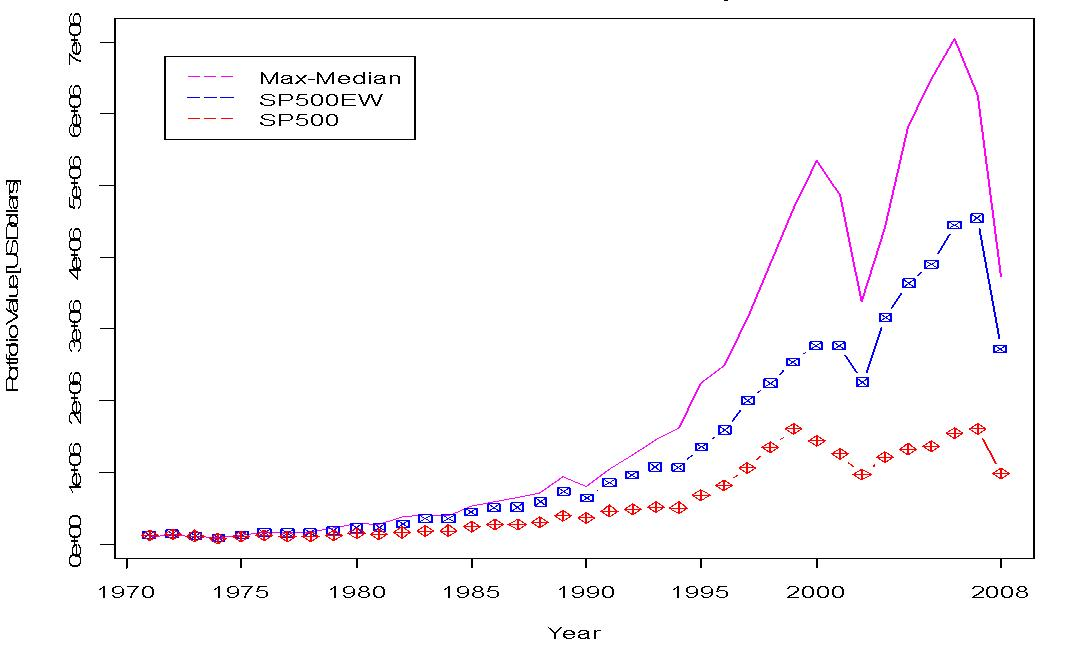
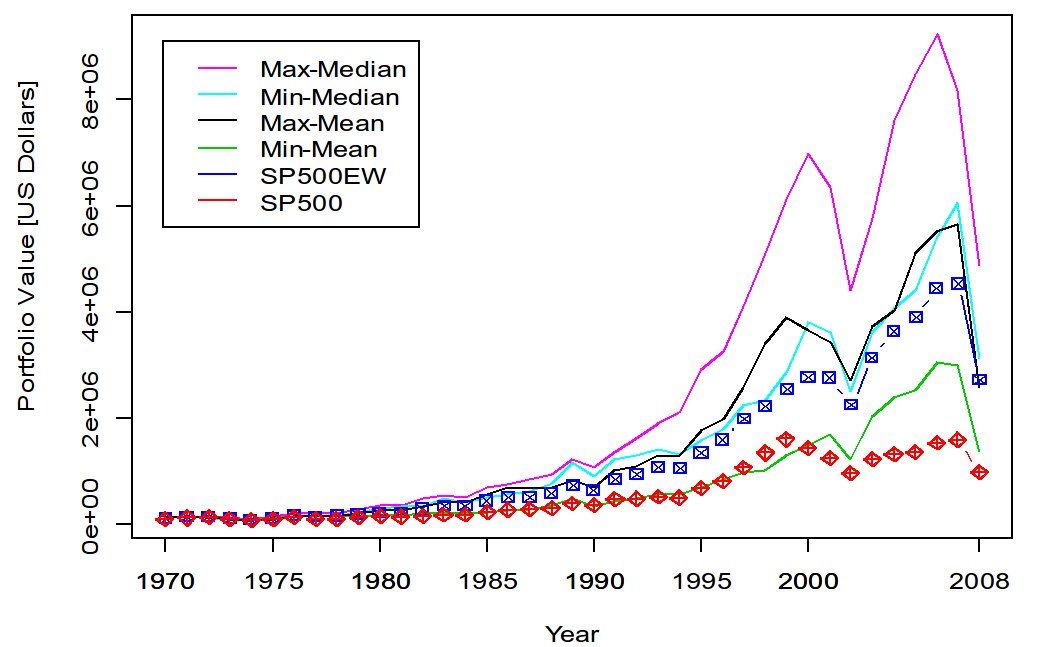
Several simulations were run with observed, above average performance (number of portfolios inspected per simulation was in the range of to ). Figure 1 shows a simulation of portfolios per year over a period of 43 years. Several interesting features can be noted through this figure. We can appreciate that any investor that made up a portfolio with an initial investment of $100,000 in 1970 and selected the same stocks chosen by our algorithm would have allowed his or her portfolio to compound to a total of $3.7M (by the end of 2008), which performed better than both an equal-investment strategy in the S&P 500 Index (about $2.7M) or a market-cap weighted investment strategy in the S&P 500 Index (slightly below $1M). Of course, we can imagine that the computational power that was used was not available in the early seventies, but moving forward it will be and to an extent this is what matters. Also it is clearly seen that the Coordinated Max-Median Rule is inherently a more volatile rule (as compared to the S&P 500). Next, Figure 2 describes 1 of 3 pilot runs that were evaluated with various measures suggesting the superiority of the max-median (as opposed to, say for instance the mean, as well as the benefit of using the “max” rather than the “min”). This seems plausible, at least heuristically, as the median is most robust (the mean is least robust), and in some sense the previous years “best” performing companies are more likely to perform better next year than the previous years “worst” performing companies (in terms of returns).
Notification Switch
Would you like to follow the 'The art of the pfug' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|